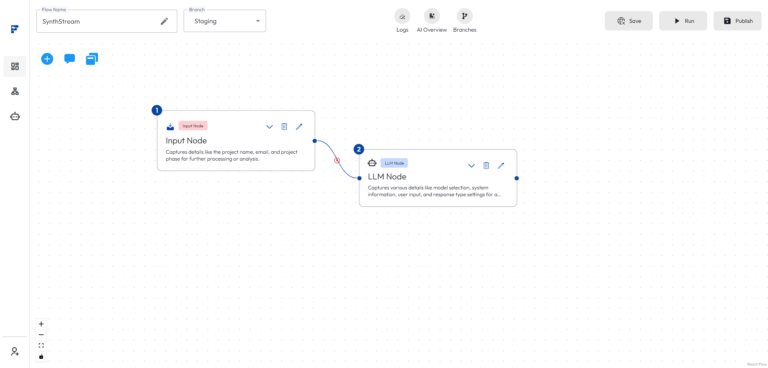
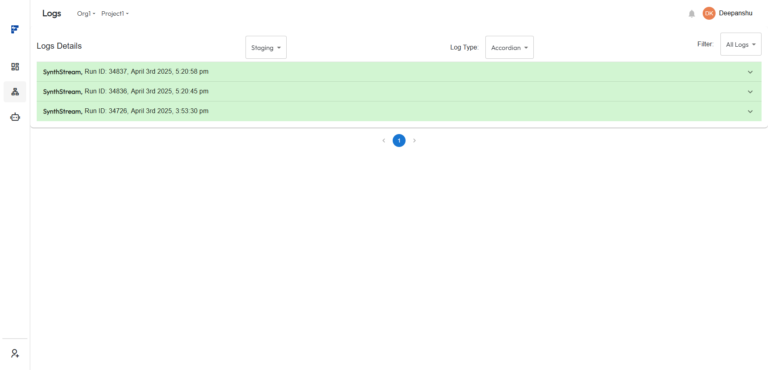
Flashbuild supports two log views to suit different use cases:
1. Flow View
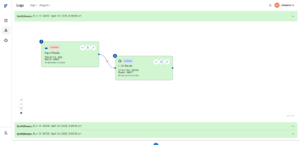
- Visual representation of the executed flow. Each node is color-coded to reflect its execution status:
1.
 Green – Node executed successfully.
Green – Node executed successfully.2.
 Red – Node encountered an error.
Red – Node encountered an error.3.
 Purple-Blue – Node was not executed (due to branch conditions or earlier failures).
Purple-Blue – Node was not executed (due to branch conditions or earlier failures). - Helps visually trace failures and understand flow paths.
2. Accordion View
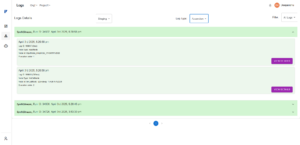
- Log data shown as expandable panels.
Each node displays:
1. Log ID
2. Execution time
3. Node Type
4. Node ID
Execution Order (represents the sequence in which the node was triggered) - Users can click “View Details” to expand the node’s execution record.
- On clicking View Details in Accordion View:
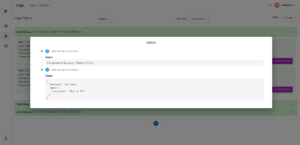
- See the exact input data that entered the node.
- See the output response or result from the node.
- Helps validate logic and debug failures by reviewing real data in and out of each node.